مشهد - بلوار کوثر - کارخانه نوآوری
۰۹۱۵ ۷۷۹ ۷۳۱۵

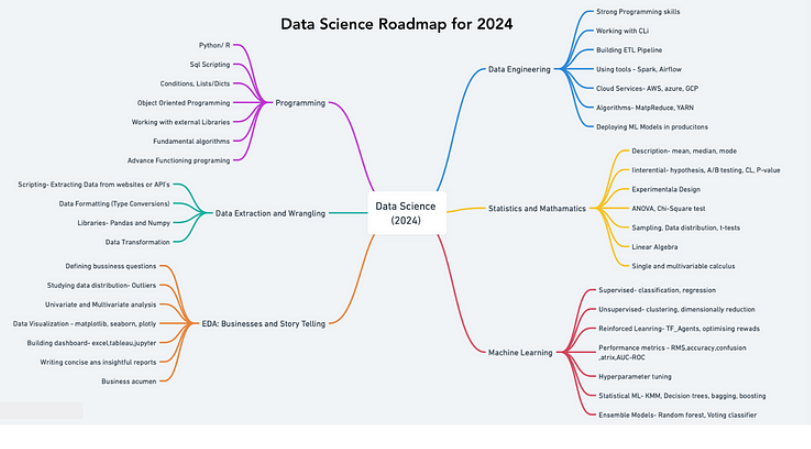
این مقاله یک نقشهراه ساختاریافته برای افرادی که به دنبال برتری در علم داده تا سال 2024 هستند، ارائه میدهد. اهمیت ایجاد مهارتهای برنامهنویسی، به ویژه در پایتون، مورد تأکید قرار گرفته و حوزههای کلیدی مانند جمعآوری داده، تمیز کردن داده، تحلیل اکتشافی داده و آمار کاربردی پوشش داده شده است.
این نقشهراه شامل برآورد زمان برای هر مرحله یادگیری است، کاربرد عملی از طریق پروژهها را تشویق میکند و پیشنهاد میکند به مهندسی داده و یادگیری ماشین پرداخته شود. همچنین بر لزوم داشتن پایهای قوی در آمار و ریاضیات تأکید دارد و به کاربردهای یادگیری ماشین و هوش مصنوعی مینگرد. هدف این است که به یادگیرندگان مهارتهایی ارائه شود که بتوانند تخصص خود را نمایش دهند، بینشهای تجاری استخراج کنند و یافتههای خود را بهطور مؤثر منتقل کنند.
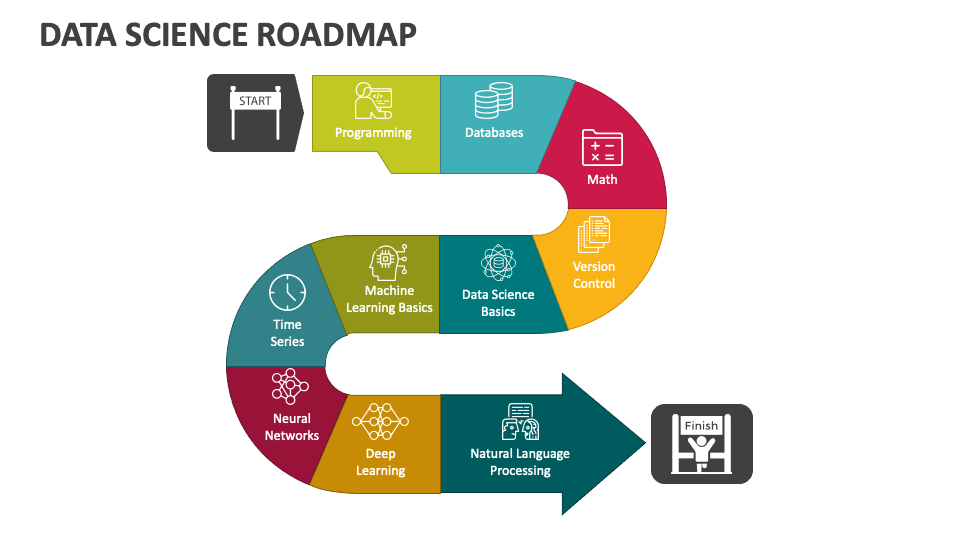
این نقشه راه سطوح مختلف مهارت را مشخص میکند و توضیح میدهد که چه مهارتهایی را میخواهید تقویت کنید، چگونه پیشرفت خود را پیگیری خواهید کرد و چه روشهایی برای تسلط بر هر مهارت به کار گرفته میشود.
هر مرحله در این نقشه راه بر اساس کاربرد عملی و میزان سختی آن ارزش گذاری شده است.
به نمودار زیر که سلسله مراتب نیازها را نشان میدهد، توجه کنید:
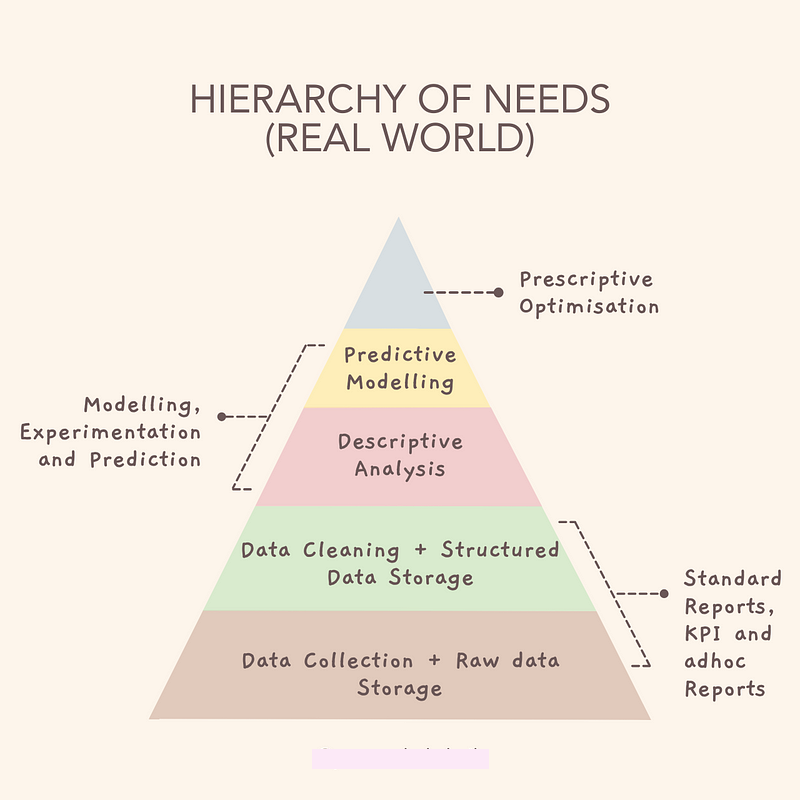
این سلسله مراتب، نقطه شروع برنامه ماست.
با تمرکز روی موضوعات مهم در هر بخش و پیدا کردن ابزارهای مناسب برای یادگیری آنها، میتوانیم برنامهمان را دقیقتر کنیم. برای اینکه ببینیم چقدر یاد گرفتهایم، باید سعی کنیم آنچه را میدانیم در پروژههای واقعی مختلف به کار بگیریم.
بیایید به هر یک از این لایهها عمیقتر بپردازیم.
گام اول: ایجاد درک قوی از برنامهنویسی.
تقریباً هر شغل مرتبط با علم داده نیاز به تسلط بر حداقل یک زبان برنامهنویسی دارد. این مرحله شامل آشنایی با ساختارهای دادهای بنیادی مانند لیستها، دیکشنریها و مجموعهها، ایجاد توابع، بهکارگیری تفکر منطقی، فهم جریان برنامهنویسی، تسلط بر الگوریتمهای جستجو و مرتبسازی، مهارت در برنامهنویسی شیءگرا و استفاده از کتابخانههای موجود در زبان پایتون است. علاوه بر این، باید با نوشتن اسکریپتهای SQL برای اجرای کوئریهای پایگاهداده شامل جوینها، توابع تجمیعی و زیربرنامهها آشنا شوید. همچنین، داشتن تجربه کار با ترمینال، کنترل نسخه Git و GitHub در این مسیر می تواند مفید باشد.
گام دوم: جمعآوری، پاکسازی و آماده سازی دادهها. جمعآوری دادهها، یک بخش حیاتی در علم داده است. باید توانایی جمعآوری داده از منابع مختلف، مانند وبسایتها (در صورت مجاز بودن)، APIها، پایگاههای داده یا مخازن عمومی را به دست آورید. پس از جمعآوری دادهها، باید به پاکسازی و آمادهسازی آنها بپردازید.
پاکسازی دادهها شامل حذف یا جایگزینی مقادیر گمشده (missed value)، رفع ناسازگاریها و استانداردسازی دادهها(Data Normalize ) می باشد. برای این کار می توانید از کتابخانههای Pandas و NumPy استفاده کنید. مهارت در جمعآوری و پاکسازی دادهها یکی از کلیدیترین بخشهای هر پروژه علم داده است، زیرا دادههای تمیز و آماده، نتایج بهتری در تحلیلها به ارمغان میآورد.
گام سوم: تحلیل دادههای اکتشافی . در این گام معمولا هدف تحلیل و تجسم داده هاست.
1- تحلیل اکتشافی دادهها (Exploratory Data Analysis – EDA) شامل مراحل زیر میشود.
2- تصویریسازی دادهها:
استفاده از کتابخانههای Matplotlib، Seaborn و Plotly برای ایجاد نمودارها و گرافهای تعاملی.
یادگیری بهترین روشها در طراحی بصری برای اطمینان از این که بینشها به وضوح منتقل میشوند.
3- ساخت داشبوردها:
یادگیری خلاصهسازی و ارائه دادهها به صورتی که برای تصمیمگیری کسبوکار مفید باشد.
استفاده از ابزارهایی مانند Tableau، Power BI یا Dash (در Python) برای ساخت داشبوردهای تعاملی و گزارشهای زنده که به تیمها و مدیران در تصمیمگیری ها کمک کنند.
گام چهارم: کاوش در مهندسی داده
مهندسی داده نقش کلیدی در شرکتهای دادهمحور دارد و اطمینان حاصل میکند که دادههای تمیز و ساختارمند در اختیار تیمهای تحقیقاتی قرار میگیرد. مهندسی داده، حوزهای متمایز و ضروری است که برای مدیریت و بهینهسازی سیستمهای داده به کار میرود.
گام پنجم: تسلط بر آمار و ریاضیات کاربردی
آمار اساس علم داده است. بسیاری از مصاحبهها بر آمار توصیفی و استنباطی تأکید دارند، در حالی که برخی بدون درک قوی از اصول آماری وارد کدنویسی الگوریتمهای یادگیری ماشین میشوند که اثربخشی کمتری دارد.
گام ششم : شروع با یادگیری ماشین و هوش مصنوعی
پس از درک اصول بنیادین، زمان آن است که به الگوریتمهای پیشرفته یادگیری ماشین بپردازید. این مرحله یادگیری را میتوان به سه دسته تقسیم کرد:
1- یادگیری نظارتشده (Supervised Learning)
مسائل رگرسیون و طبقهبندی: یادگیری نحوه پیشبینی مقادیر پیوسته و طبقهبندی دادهها به گروههای مختلف.
مدلهای مختلف هوش مصنوعی مانند:
2- یادگیری بدون نظارت (Unsupervised Learning):
3 – یادگیری تقویتی (Reinforcement Learning)
ساخت شبکههای Deep Q جهت یادگیری تکنیکهای پیچیدهتر در یادگیری تقویتی و استراتژیهای عمل. این بخش در مقالات آینده بیشتر توضیح داده خواهد شد.