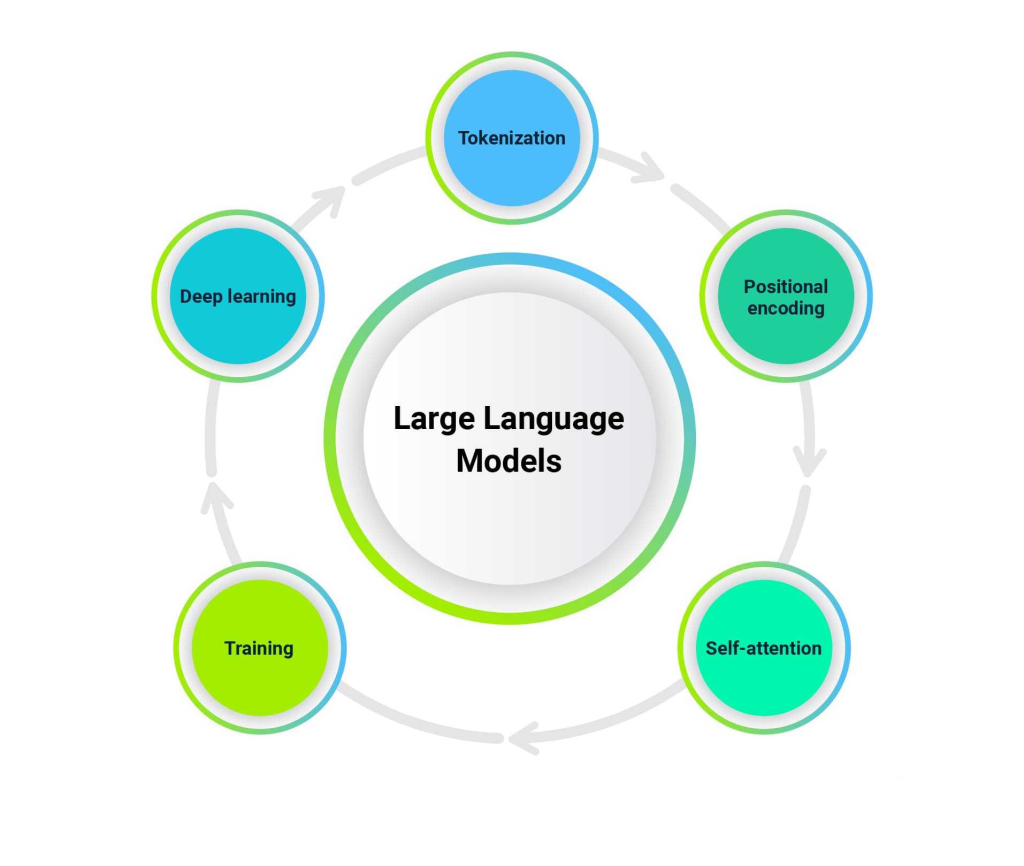
مدلهای زبانی بزرگ (LLM) مانند GPT امروزه محبوبیت زیادی پیدا کردهاند. این مدلها به چتهای دیجیتال قدرت میدهند، عبارات پیچیده را درک میکنند و حتی مانند انسانها مینویسند.LLM ها با استفاده از تکنیکهای یادگیری عمیق و شبکههای عصبی ترنسفورمر و نیز مجموعهدادههای عظیم، توانایی درک متون و پاسخ به کاربر را دارند. اما سوالی که مطرح است این است که چگونه میتوان فهمید کدامیک از این مدلها کارایی مدنظر را دارند و با توجه به اینکه LLMهای جدید به طور مداوم تولید و ارائه میشوند، چگونه میتوان عملکرد آنها را ارزیابی و مقایسه کرد؟
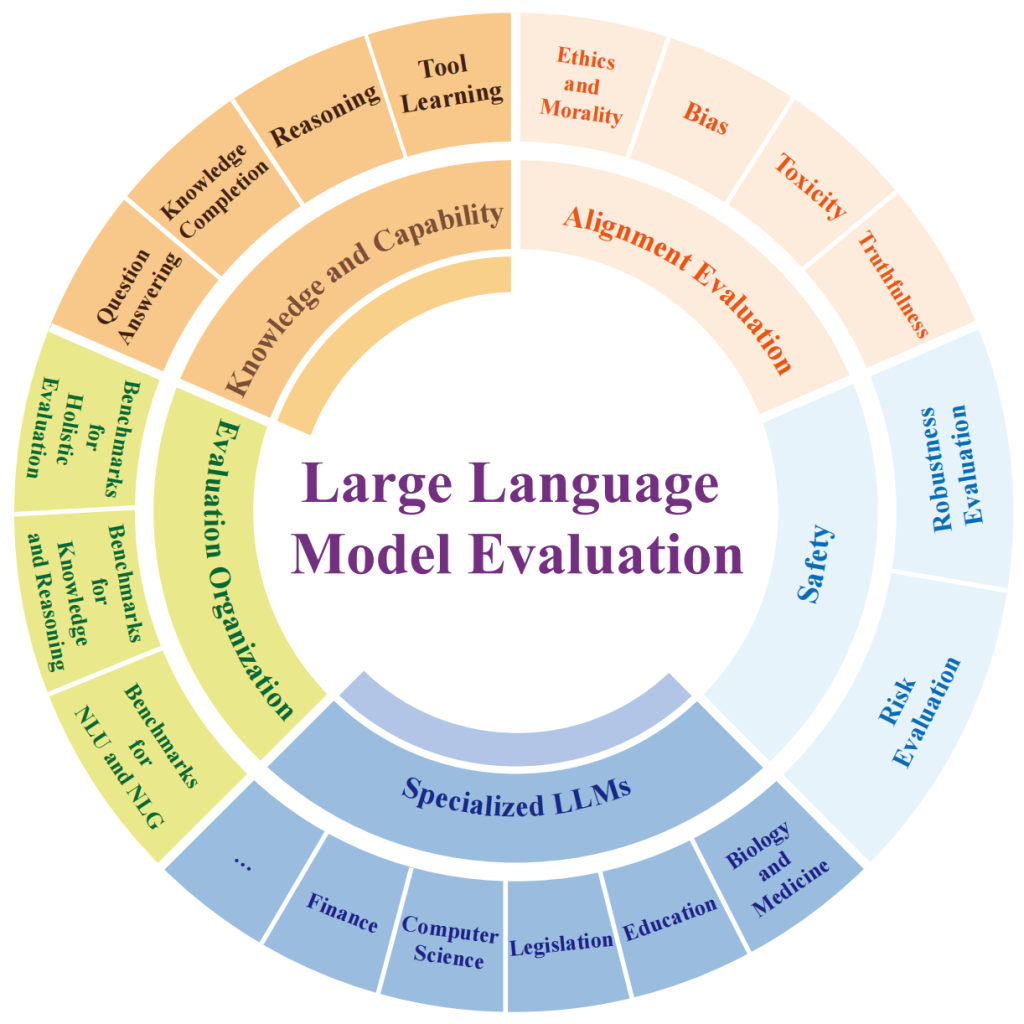
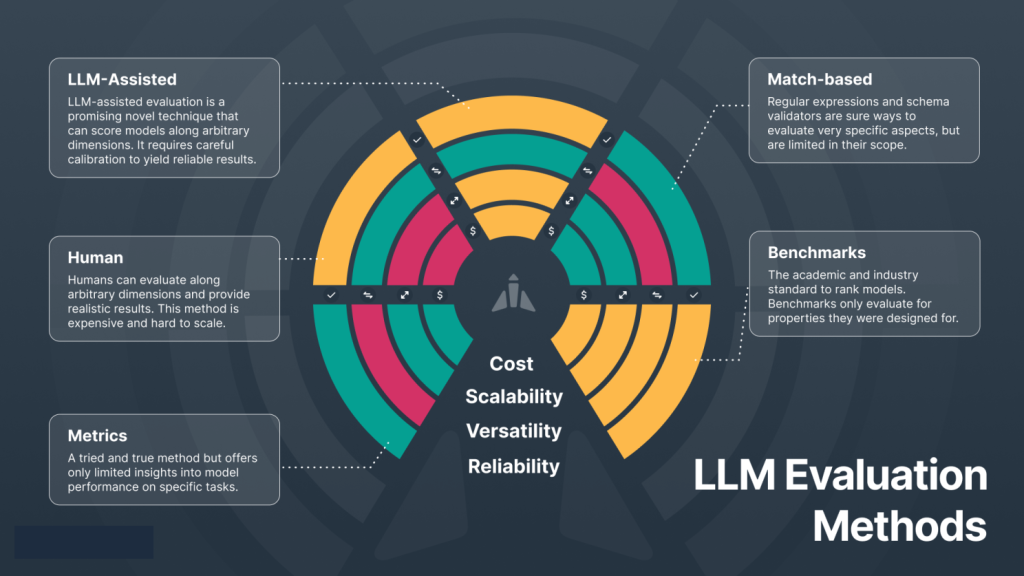
از آنجایی که کارایی مدلهای هوش مصنوعی با توان انسانی مقایسه میشود، در برخی ارزیابیها نیز روش ارزیابی شبیه به ارزیابی انسانها خواهد بود. برای مثال، هنگامی که افراد را برای شغلی استخدام میکنیم، با توجه به وظایف تعریفشده برای آن شغل، با داوطلبان مصاحبه کرده و از آنها امتحان میگیریم. برای ارزیابی مدلهای زبانی نیز میتوان از این روش استفاده کرد؛ به این صورت که یا یک ارزیاب انسانی مدلهای زبانی بزرگ را ارزیابی کند، یا آزمونهایی برای ارزیابی مدل تدوین شود. این آزمونها باید برای ارزیابی کارایی مدلهای زبانی بزرگ در انجام وظایفی مانند خلاصهسازی، استدلال، پاسخ به سوالات و ترجمه متن و بسیاری وظایف دیگر طراحی شوند. این آزمونها میتوانند شامل سوالات تشریحی، چند گزینهای و به هر شکل دیگری باشند. بنابراین، نیاز به ابزار ارزیابی (مثلا LM evaluation harness) و معیارهایی برای اندازهگیری و همچنین مجموعه دادههای معیاری برای این کار داریم.
با توجه به اینکه مدلهای زبانی زیادی در حال ساخت هستند، ارزیابی مدلهای زبانی بزرگ بسیار مهم است. این ارزیابیها میتوانند تأثیرات اجتماعی و اقتصادی قابل توجهی داشته باشند، به ویژه در کاربردهایی مانند خدمات مشتری و تولید محتوا. همچنین، چالشهایی از جمله تعصبات موجود در دادههای آموزشی و پیچیدگیهای فرهنگی و زبانی ممکن است بر نتایج ارزیابی تأثیر بگذارند. به همین دلیل، توسعه و استفاده از ابزارهای جدید و تکنیکهای پیشرفته در ارزیابی مدلهای زبانی از اهمیت ویژهای برخوردار است. به منظور دستیابی به این هدف، محققان و توسعهدهندگان میتوانند از ابزارها و منابع مختلفی استفاده کنند. با جستجوی کلماتی مانند “leaderboard LLM evaluation” میتوانید رتبهبندی برخی از مدلهای زبانی در وظایف مختلف را پیدا کرده و با توجه به نیاز خود از آنها استفاده کنید. این رتبهبندیها و معیارهای ارزیابی میتواند به انتخاب مدل مناسب برای کاربردهای مختلف کمک کند و تضمین کند که مدلهای زبانی به طور مؤثر و کارا در محیطهای واقعی مورد استفاده قرار میگیرند.